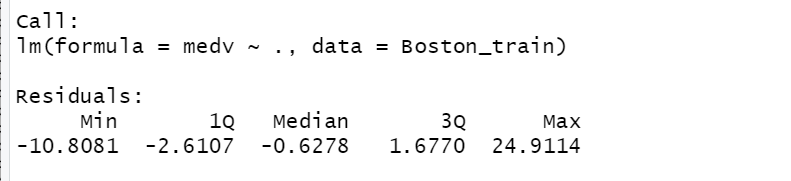| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- 환경구축
- 데이터마이닝
- 오라클
- 로지스틱
- 장고
- 하둡
- 머신러닝
- 머신러닝 #머신러닝 종류
- R 스튜디오
- 페이지 연결
- 글쓴이 추가
- JSP
- 스프링 검색
- 장고 #네비게이션
- 랜덤포레스트
- 개발환경
- mariadb # mariadb 다운로드
- 환경설정
- MyBatis
- 데이터 마이닝
- mvc 구조
- 에외처리
- DB
- 데이터 베이스
- 영상처리
- jsp 환경 #환경구축 #웹사이트 구축
- 데이터
- 장고 # 댓글추가
- 스프링
- 웹 스프링
- Today
- Total
공부잡동사니
머신러닝 본문
머신러닝
-인공지능의 한 분야로 컴퓨터가 학습할 수 있 도록 하는 알고리즘과 기술을 개발하는 분야.
-컴퓨터가 외부에서 주 어진 방대한 빅데이터 를 통해 스스로 학습하 는 기술
-프로그램을 작성하지 않고 컴퓨터에 학습할 수 있는 능력을 부여하 기 위한 연구분야
-기계가 데이터로부터 여 러번의 시행착오를 통해 서 프로그램을 스스로 학 습함으로써 성능을 향상 시키는 인공지능의 기술
머신러닝의 분류
- Supervised Learning(지 도학습) : 미리정의 된 정답지가 있는 모델
-Unsupervised Learning(비지도학습): 미리정의 된 응답지가 없음
-Others:Reinforcement learning, recommender system,

정의
머신러닝 구성요소 설명
-작업은 모델에 의해 다루어지고 학습문제는 모델을 생성하는 학습알고리즘들에 의해 해결된다.
-모델은 머신러닝 분야에 다양성을 제공하지만 작업 과 특징은 통일성을 제공한다.
-머신러닝은 정확한 작업을 성취할 수 있는 올바른 모델들을 구축하기 위해 올바른 특징을 활용하는 것 이다.
Data Set 분활하기
머신러닝기반데이터 분석 진행시 한꺼번에 분석 하지 않고 분활하여 진 행하게 됨.
데이터 세트준비
-과적합 : 훈련데이터만으 로는 세트의 패턴만 잘표 현하게되는 너무 많은 데 이터의 반영이 되어서 일 반화 능력이 떨어질 수 있 음
RMSE(Root Mean Squared Error)에서 보면 머신러닝 기 법유연성의 증가함에 따라, 즉 다항식차수가 증가함에 따라 패턴과 일치성이 증가 하는 경향이지만 일정수준 이후로는 오차가 증가함.
이런 의미에서 평가데이터가 필요함.

Data Set 분활하기
일정비율로 학습용과 평가 용세트로분활하기 :일반적으로 훈련데이터와 평 가데이터를 60~80/40~20으 로 할당한다. 단 실무상황 에선 담당자의 경험과 판단 으로 결정할 수 있음.
평가데이터를 이용한 모델 성능평가 후 최종모델확정 :만들어진 모델을 평가데이터 에 의해 성능평가하고 만족 스럽지 못하다면 다시 피드 백하여 다시 진행
학습데이터로부터 머신 러닝 모델링 수행 :수행한 모델링을 통해 기 법이나 추정방법등을 통해 최종모델 구성.

Data Set 분활하기
학습용 데이터와 평가 용 데이터로 분활 한다
학습데이터를 이용한 머신러닝 수행 및 평가 데이터를 이용한 모델 성능평가
분활방법 실습
일관성 여부 확인 -sampleBy -createDataPartition
최종모델 성능평가
[iris data 예제]



문제점
연속적인 순서대로 인덱스화 된 데이터는 일관되지 못하 는 경우로 편중되어 추출됨. 무작위 샘플추출에 의한 분 활 데이터가 필요함
data set 분할



데이터의 빈도 일관성 여 부 확인의 필요성 :전체데이터의 7:3비율이지 만목적변수의 일관성 차 이들은 좋은 성능의 알고 리즘을 기대하기 어렵기 때문임


문제점 :위의 학습용/ 평가용의 각 종 속변수의 빈도수가 차이를 보이기 때문에 위에 대한 속 성분포에 따른 목적변수의 표본추출이 필요함

doBy의 불편함 존재 :첫번쩨 세트에 포함되지 않는 나머지 데이터를 2 단계로 추출해야 되는 번거러움이 존재 함

훈련데이터의 평가데이터가 목 적변수의 속성내용에 빈도분포 가 모두 동일하게 추출됨을 확 인함.
-훈련데이터 머신러닝 수행
-평가데이터 모델성능 평가
지도학습 모델 적용하기
-학습목표 :예측 모형화를 위해 적합 한 머신러닝 기법 :최적분류 모델선정 적용
-분류목적을 위한 머신 러닝으로는 종속변수가 이산형이거나 명목특성 의 경우 사용되는 기법 임.
-분류목적의 활용 영역
-스팸메일분류 -
기업부도/정상예측
-고객이탈/유지예측
-고객신용등급 판별
-특정질병 발생여부예측
-고객의 구매여부 예측 등
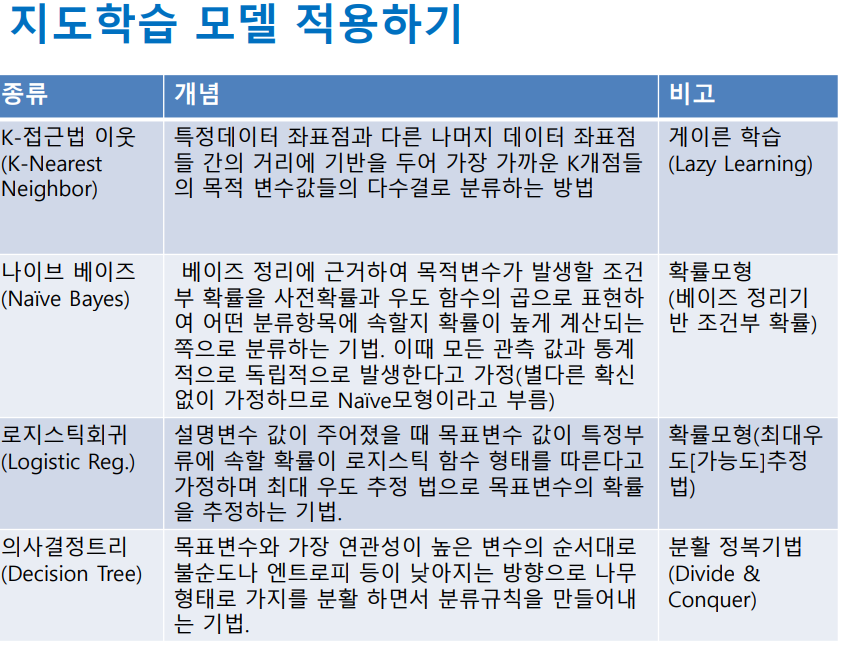
-분류목적의 머신러닝 알고리즘은 매우 다양 하며 약 7개종류의 알고 림즘으로 구성되어 있음.

K-최근접 이웃(K-Nearest Neighbor)
개념 -목표변수의 범주를 알지 못하는 데이터세 트의 분류를 위해 해당데이터세트와 가장 유사한 주변데이터 세트의 범주 로 지정하는 방식의 분류 예측법. -최종적으로 목표변수의 범주를 분류할 때 주변데이터 세트 몇 개를 기준으로 판 단 할것인지 기준이 필요함. • 유사성 측정방법 사용 :두 점간의 유클리드안 제곱거리의 역 수를 취하거나 피어슨 상관계수를 이용하여 유사성을 계산 함. :목표변수의 가장최근점에서의 ‘K’개 는 참조할 주변데이터들과의 개수 를 의미함.

’K-근접이웃’이라 함.
K-1근접이웃은 원,
K-3근접이웃은 사각형,
K-5근접이웃은 원이라고 할 수 있음.
평가용데이터를 이용하면서 K값의 근접이웃을 추정할 필요가 있음.

활용분야
-모바일 추천시스템
-상품 및 서비스 추천 등
수식적용 계산된 거리를 이용하여 k개 의 인접이웃 를 알아내 면 가장 많은 label를 다 수결로 선발하여 우리가 구하는 솔루션으로 함

Dx 는 x를 중심으로 하는 반경 안의 데이터들의 집합. Argmax 라는 함수는 뒤에 있는 수식이 최대가 되는 변수 y를 찿는것이다


혜영이가 만난 모든 남자들 의 프로필을 요약하여 속성 집합을 만들어서 남자들의 선호도를 마음이드는 사람 은 1타입, 호감만 가는 사람 은 2타입, 아무감정이 없는 사람은 3타입으로 설정함.

친구인 지혜로부터 소개 받은 훈남이라고 생각한 남성의 데이터를 받아 이 를 적 용하여 k-nearest Neighbor를 적용하고자 한다.

베이즈기법은 베이즈확률 추정 에 기반을 둔 확률모형이다. • 사건B가 일어났을때 사건A가 일어날 확률, 즉 조건부 확률 P(B|A)의 곱을 사건 B가 일어날 확률 P(B) 로 나누어 알아낼 수 있다는 것임.





민감도 특이도를 참고를 해야한다
종속변수가 범주를 분류 하고자 할때 사용한다.목 표변수 y가 특ㄱ정 범주 가 될 확률 . 목표변수 Y 가 특정범주(i)가 될 확률 P(Y=i)이다.



장점
-선형통계모형의 이론에기반한 정교 하고 체계적인 모수추정 가능
. -확률모형이므로 목표변수의 범주 확 룰값을 추청
-추정된 모형의 계수에 대한 해석이 가능
-독립변수들의 유의성 여부가 파악 됨. •
단점
-모형의 추정 정확도가 타 머신 러닝 기법 에 비해 좋지 않음
-복잡한 비선형적 분류가 필요한 경우에는 분류 정확도가 좋지 않음.
-추정방법상 x값이 메우 커지거나 작아지 면 확률값이 1,0에 가까워져서 숯치계 산 정확도가 매우 떨어지게 됨
. 즉 반 복계산시 오버피팅이 빈번하게 발생함.




의사결정 나무
종속변수와 독립변수의 속성기준값에 따라 트리 구조의 형태로 뿌리노드 로부터 잎노드까지 뻗어 나가며 모델링을 하는 기 법을 말함.
나이가 뿌리노드이며 나중의 사각형 노드가 잎(리프)노드임.
분류기준은 불순도, 엔 트로피 지수등이 있다.


활용분야로는 고객신용등 급평가/고객만족도 분석 에 따른 이탈예측/기업의 부도예측/주 가예측/환율 예측/경제전망 등에 사용 됨




인공신경망
인공신경망은 생물체의 신경망을 모사하여 입 력신호와 출력신호간의 관계를 모델화 하는 기 법임.

신호와 중요도에 따른 가중치 를 부여하여 가중합을 계산하 고 활성함수 f(시그모이드함수) 를 적용하여 결과값 y를 출력 하는 형태라고 볼 수 있다. 이 를 표현한것이 퍼셉트론(신경 망구조)이라 하며 단층혹은 은닉층이 추가된 다층구조 가 있다.








SVM은 분류하는 경계선 을 잡기위해 도입하는 하 나의 벡터를 지지벡터라 고 하는데서 비롯된것이 다. 이에 대한 선형SVM 이 있고 비선형 SVM이 있 다.



랜덤 포레스트
의사 결정 트리 분석의 예 측도를 높이기 위해 다수 의 의사 결정 트리 집합을 사용하여 결과를 예측하 는 앙상블 학습기법임.
서로다른 분류기가 10개가 있 을때에 각 분류기의 에러율은 20%정도일때 우선은 5개이상 이 ‘YES’일때 ‘YES’로 간주한다.
이렇게 분류기 세트로 구성하 여 처리하면 확실히 오분류가 줄어든다는 법칙이 앙상블의 효 과이다.