
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- 데이터마이닝
- 장고 # 댓글추가
- 데이터 베이스
- 영상처리
- 장고
- 머신러닝
- 환경구축
- DB
- 에외처리
- 랜덤포레스트
- mariadb # mariadb 다운로드
- 하둡
- 글쓴이 추가
- 로지스틱
- MyBatis
- 장고 #네비게이션
- R 스튜디오
- 스프링 검색
- 웹 스프링
- mvc 구조
- jsp 환경 #환경구축 #웹사이트 구축
- 개발환경
- 데이터 마이닝
- JSP
- 오라클
- 데이터
- 페이지 연결
- 스프링
- 환경설정
- 머신러닝 #머신러닝 종류
- Today
- Total
공부잡동사니
집합 연산자산 ,자료구조(행력 ,배열 ,데이터 프레임) 본문
#논리 연산자
#and:&
#2)or:1
#)not:!
# 참고 :숫자를 사용한 논리값의 전달
#0 :FALSE(0이 아니면 TRUE)
!0
!100
1&3 #true & true = true
1&0 #true &false =false


#형(데이터 타입 ) 확인함수
is.vector: 벡터 인지
is.numeric:숫자 인지
is.na :벡터의 각원소마다 NA 여부 리턴
is.null :벡터 자체가 NULL 인지 리턴


#벡터의 집합연산자
# 1)합집합:union
# 2)차집합:setdiff
# 3)교집합:intersect()
#4)동등비교 :indentical 구성 요소는 같으니나 크기가 달라서
#setequal 크기 상관없이 구성원소는 같다


#행렬:matrix
#2차원
#하나의 데이터 타입만 허용
#주로 숫자 연산을 빠르게 하기 위해 만듬
#1.생성
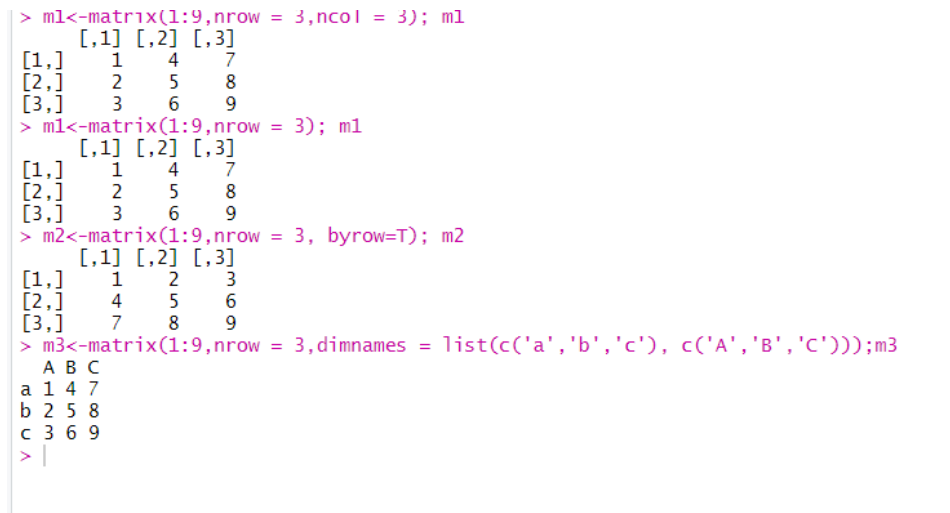
matrix(data = , #matrix 구성data(벡터)
nrow = , #행수
ncol = , #컬럼수
byrow = FALSE, #행과 우선순위 배치 여부
dimnames =)) #행과 열의 이름
m1<-matrix(1:9,nrow = 3,ncol = 3); m1
m1<-matrix(1:9,nrow = 3); m1
m2<-matrix(1:9,nrow = 3, byrow=T); m2
m3<-matrix(1:9,nrow = 3,dimnames = list(c('a','b','c'), c('A','B','C')));m3
색인






# [ 참고 : 행렬 곱 ]
# [a1,a2 [b1,b2
# a3,a4] b3,b4]
#
# (2X2) * (2X2) = (2X2)
# (3X2) * (2X6) = (3X6)
#
# a1*b1 + a2*b3, a1*b2 + a2*b4
# a3*b1 + a4*b3, a3*b2 + a4*b4

#배열 :array
1.생성
array(data = , # 배열을 구성하는 data 벡터
dim = , #차원
dimnames =) #각차원의 이름


#참고:다차원의 배열 순서 비교
#in R )
#행 열 층 ...
#in python 행열
#... 층 행 열
#2.색인
a1<-array(1:18, dim = c(3,3,2))
a1[, ,1] #첫번쨰 층층
a1[1, ,1] #각층의 첫번쨰 행
a1[,,1,drop=F]#일부는 가능 하나 일부는 불가능 하다
a1[1,,drop=F]#사용불가

#데이터 프레임
# 2차원 구조
# 행과열의 구조
# 열은 key 를 갖는구조
# 엑설에서의 표 ,데이터 베이스에서의 테이블과 비슷

#2.구조확인
ncol(df1)#컬럼수
nrow(df1)#행의 수
dim(df1)#행과 컬럼의수
rownames(df1)#행 이름
colnames(df1)#컬럼 이름
str(df1) # 데이터 사이즈 확인못함

#3.색인
df1[1,1] #위치 색인
df1[1,'ename'] #이름 색인
df1[ ,'ename']#특정 컬럼 하나의 선택은 차원 축소됨
df1[,'ename',drop=F]#차원 축소 방지가능
df1$ename #key 색인








'빅데이터 분석 > R프로그래밍' 카테고리의 다른 글
| 재귀함수 (0) | 2025.04.05 |
|---|---|
| 문자열 함수 정리 ,NA치환 ,반복문 for ,while ,factor 변수 (0) | 2025.04.05 |
| 조건문 (if) , 반복문(for) , 반복문 함수 (0) | 2025.04.05 |
| 자료 구조 (벡터,리스트)논리 연산자 (0) | 2025.04.05 |
| R(1) 변수 확인 타입 제거 날짜 산술 연산 (0) | 2025.04.05 |



