
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 |
- 하둡
- 데이터마이닝
- 장고 #네비게이션
- 스프링
- jsp 환경 #환경구축 #웹사이트 구축
- 장고
- 웹 스프링
- 로지스틱
- 페이지 연결
- DB
- qe #qa #qc
- 환경구축
- 오라클
- mariadb # mariadb 다운로드
- 머신러닝
- 데이터 베이스
- JSP
- 환경설정
- 스프링 검색
- 장고 # 댓글추가
- 영상처리
- 글쓴이 추가
- 머신러닝 #머신러닝 종류
- 랜덤포레스트
- mvc 구조
- #도커 #도커개념 #도커장단점
- 에외처리
- 데이터 마이닝
- MyBatis
- R 스튜디오
- Today
- Total
공부잡동사니
군집분석(계층적 군집 분석,NBClust,kmeans(비계층적군집분석)(R) 본문
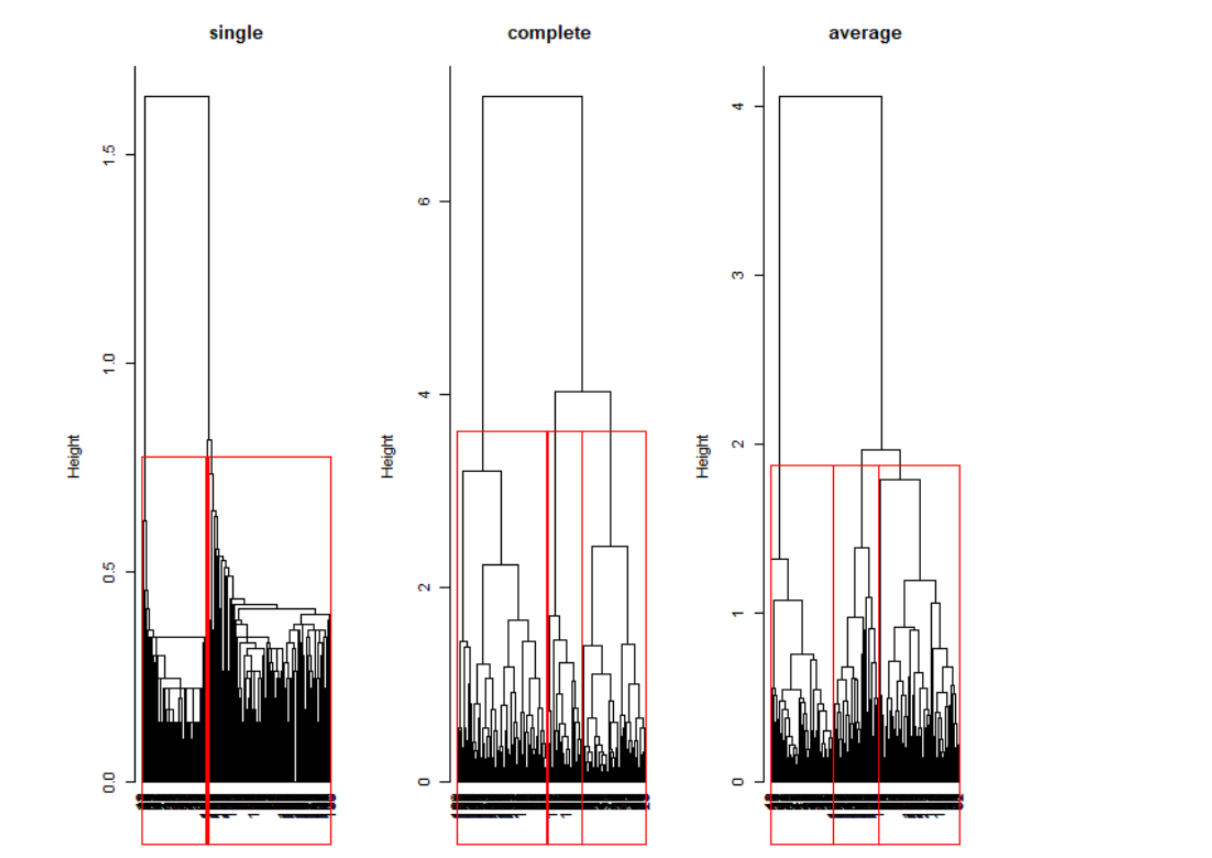
1.계층적 군집분석
-거리가 가까운 데이터 포인트들 끼리 순차적을 묶는 형식
-하나의 데이터가 한 군집에 속하면 군집은 변경되지 않음
-군집 형성 과정(군집과 데이터 포인트와의 거리 측정 방식에 따라)




[참고]
NbClust
-install.packages('NbClust')
-library(NbClust)
-nbclust 패키지 적절한 k의 수를찾아줌
-26개 지표값을확인할수 있음
-Dindex 지표 :그룹내 분산에의해 계산된지표 작을수록 좋다
-sDindex 지표:그룹분산및 중심의 평균으로부터 계산된 지표 클수록 좋다






[군집 분석에서의 분산]
1.총분산(total_ss)
-그룹과는 상관없이 관측치들의 총분산
2.그룹내 분산(within_ss)
-각 클러스터의 중심으로부터 각 클러스터 관측치가 떨어진 정도
-그룹내 분산은 작을수록 좋은 클러스터링 결과
-그룹의 개수가 커질수록 그룹내 분산도 작아짐
3.그룹간 분산(between_ss)
-각 클러스터의 중심으로 전체중심으로 흩어진 정도
-그룹간의 분산은 클수록 각 클러스터의 이질성을 대변하므로 좋은 결과
-그룹의 개수가 커질수록 그룹내 분산도 커질수도 있다
그룹내 분산이 작을수록 그룹간 분산이클수록 좋은 군집분석
total_ss=between_ss+within_ss
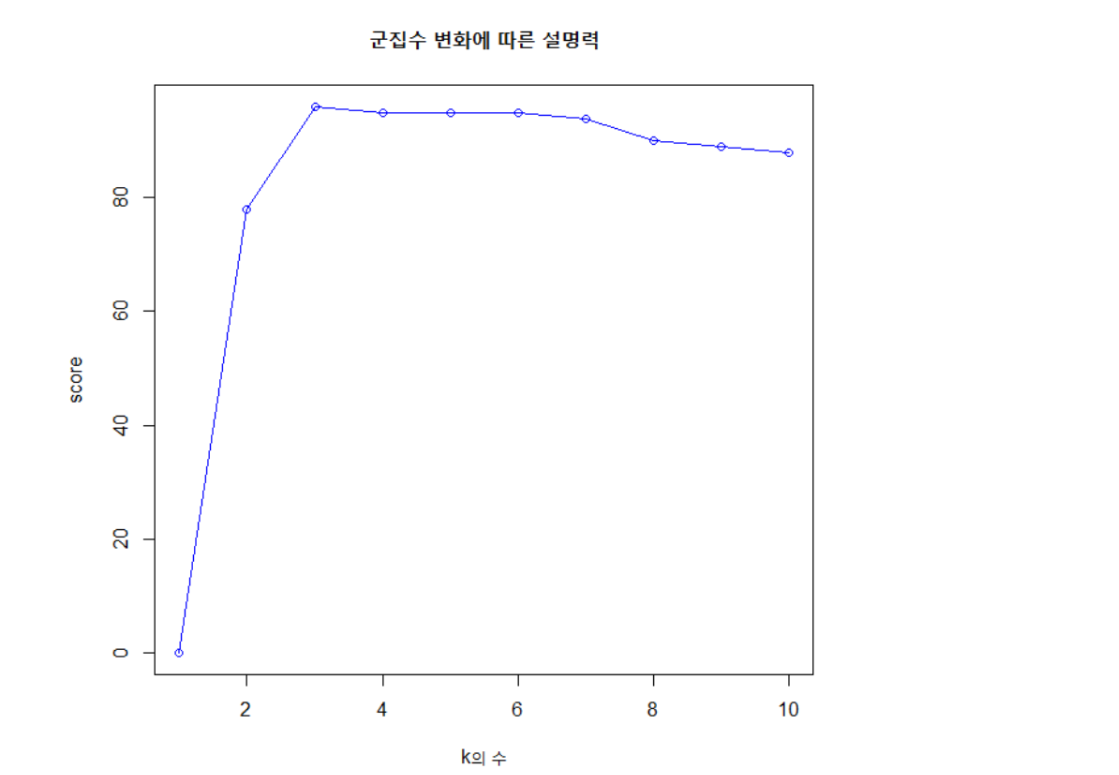
[2.비계층적 군집분석]
-거리가 짧은 데이터 포인트끼리 묶는 방식은 동일
-계층적 군집분석과는 다르게 한번 클러스터에 소속된 관측치도 거리 측정 대상에 포함시켜 만약 다른 클러스터와 거리가 더짧다면
-다른 클러스로이동되는 방식
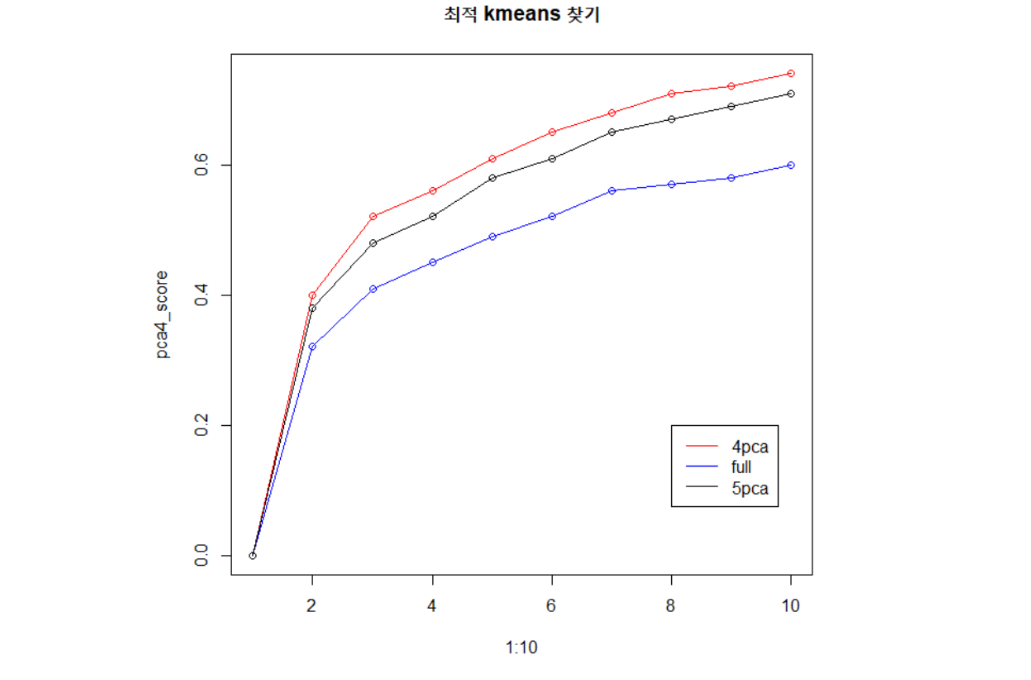
-평가 metric(그룹내/그룹간 분산에 의한 score )
-사용자가 직접군집의 수를 정하면 해당 군집에 맞게 분류
kmeans(x, 원본 data 거리 행렬 x
cneters=) -군집갯수
군집분석 수행(모델링)

[비계층적 군집분석 수행방식]
-1.사용자가 지정한 k의 수 만큼 랜덤하게 초기 중심(seed)값 추출
-2.위seed 로부터 각 관측치와의 거리 계산
-3.거리가 가장 가까운 관측치들을 각 클러스터에 할당
-4.변경된 클러스터의 중심을 재계산
-5.재계산된 클러스터의 중심으로 전체 테이터의 거리 모두 계산
-6.각 클러스터의 중심으로부터 가까운 클러스터 포인트 소속/이동
-7.위 과정을 더이상 중심이 이동되지 않을때까지 계속 반복
-8.그룹고정




'빅데이터 분석 > 머신러닝' 카테고리의 다른 글
| 데이터분석 ,mglearn(시각화 모듈 ),KNN (p) (0) | 2025.04.06 |
|---|---|
| 변수선택법(전진,후진,stepwise)이상치 점검 (R) (0) | 2025.04.06 |
| 분류(KNN),군집분석(계층적 군집분석)(R) (0) | 2025.04.06 |
| 의사결정 나무 ,랜덤포레스트(R) (0) | 2025.04.06 |
| 데이터분석 ,분류실습(R) (0) | 2025.04.06 |



